Este artigo foi escrito por Bruno Dupire para o relatório ‘2018: Um ano de mudança para o buy side’.
Estabelecer uma ligação entre observáveis atuais — dados estruturados e não estruturados — e comportamento futuro é um grande empreendimento em finanças e, naturalmente, o setor está adotando a aprendizagem de máquina (machine learning) para abordar esta tarefa típica de aprendizagem. Isto requer a ampliação do intervalo de dados e métodos, e a mudança de alguns hábitos antigos.
Tradicionalmente, a maioria dos dados financeiros era processada de forma estruturada — como informações numéricas de mercados e preços de ativos — e os métodos de processamento eram com base no toolkit de estatística padrão. Avanços na aprendizagem de máquina (machine learning) e processamento significam que agora é possível processar (e entender) grandes quantidades de dados não estruturados, oferecendo o potencial para transformação do setor.
Relevância em conjunto de dados
Participantes do mercado estão gradativamente reconhecendo que muitas dimensões do mundo estão interligadas e que, entender esta rede de interações pode desencadear o potencial de previsão. Fontes anteriormente ignoradas, agora estão sendo exploradas para obtenção de dados importantes e potencialmente rentáveis.
Por exemplo, imagens de satélite da intensidade da luz noturna, sombras de tanques de petróleo e o número de carros em estacionamentos, podem ser usados para estimar atividade econômica. Atividade da mídia social e notícias podem ser utilizadas para determinar o sentimento, enquanto o uso de cartão de crédito pode revelar tendências importantes de gastos de consumidores.
Um primeiro conjunto de técnicas transforma os dados em um valor numérico: uma imagem de satélite noturna é convertida em uma medida da intensidade da luz; uma foto de um estacionamento é analisada para revelar o número de carros; a linguagem em um artigo de notícias ou tweet é colocada em um índice de polaridade para prever sentimento positivo, negativo ou neutro.
Um primeiro conjunto de técnicas transforma os dados brutos em um valor numérico. Por exemplo:
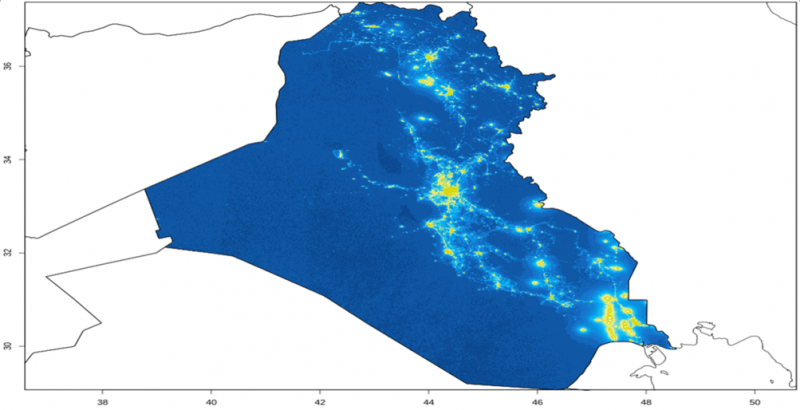
O próximo passo é usar estes dados para previsões. Podemos usar a intensidade da luz para prever as despesas vs o PIB de um país? Podemos estimar lucros observando o estacionamento do Walmart, etc.? Podemos estimar o retorno de preço ou volatilidade de uma empresa utilizando o sentimento da mídia social?
Métodos de aprendizagem de máquina (machine learning)
Há vários métodos de aprendizagem de máquina (machine learning) que podem ser usados dependendo do tipo de dados disponíveis e objetivo. Os mais comuns são:
- Aprendizagem supervisionada: neste método queremos entender a relação entre um conjunto de observáveis (entradas) e a quantidade de interesse (saídas). Começamos com um conjunto de exemplos (conjunto de treinamento) que são pares de entradas/saídas, também conhecidos como características/rótulos. O algoritmo tenta aprender a associação entre as características e os rótulos, ajustando seus parâmetros. Seu desempenho é testado em outro conjunto de exemplos (conjunto de teste) ao qual ainda não foi exposto. Este algoritmo pode então ser utilizado para prever a saída ao observar as entradas.
- Aprendizagem não supervisionada: neste método, o objetivo do sistema é encontrar uma estrutura subjacente nos dados. Um exemplo comum é o agrupamento, que encontra grupos de pontos de dados com atributos similares; outro exemplo é a redução de dimensão ou compressão de informações através de autocodificadores que são redes neurais com estreitamento.
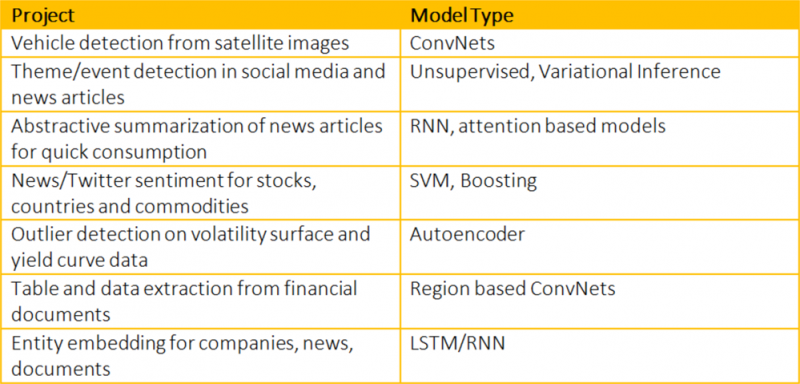
A lista de tarefas que podem se beneficiar da aprendizagem de máquina é infinita. A seguinte tabela mostra alguns dos projetos de aprendizagem de máquina (machine learning) em que estamos trabalhando na Bloomberg:
Autocodificadores para redução de dimensão
Um exemplo interessante do uso de redes neurais é a redução da dimensão de curvas de rendimento ou superfícies de volatilidade. Para curvas de rendimento, a técnica tradicionalmente mais utilizada é a Análise de Componente Principal (PCA). No contexto da curva de rendimento, os três componentes mais importantes são identificados como o deslocamento paralelo, inclinação e giro.
Uma rede de autocodificador é mais eficiente na redução de dimensão que uma PCA, porque pode utilizar a não-linearidade gerada. O objetivo de uma rede de autocodificador é reproduzir como saída a entrada inicial forçada por um estreitamento que extrai a informação de entrada em uma representação compacta. Normalmente, funciona melhor que a PCA quando há uma mudança de comportamento geral ou mudança de regras.
Podemos usar algoritmos de aprendizagem supervisionada para reconhecer sinais que podem gerar alfa ou aprender a construir portfólios para diferentes condições de mercado. Dois exemplos são:
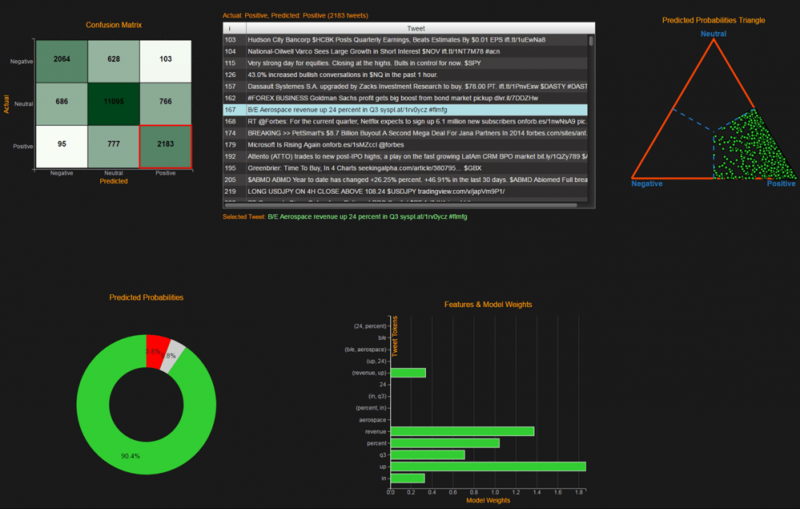
- Estratégias com base em sentimento: texto de tweets ou notícias pode ser analisado e automaticamente marcado como uma expressão de sentimento positivo, neutro ou negativo. Por exemplo, o gráfico abaixo resume o número das três classes de tweets sobre uma ação (MS) para cada intervalo de 15 minutos, em um período de 2 dias.
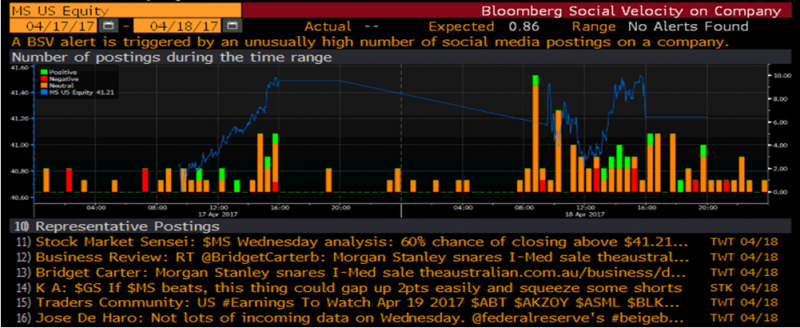
A análise destes dados processados resultam em sinais de negociação que podem ser usados para construir uma estratégia de negociação, tomando uma posição longa em ações de sentimento positivo e curta nas de sentimento negativo. No gráfico abaixo vemos que tal portfólio supera significativamente o desempenho do mercado.
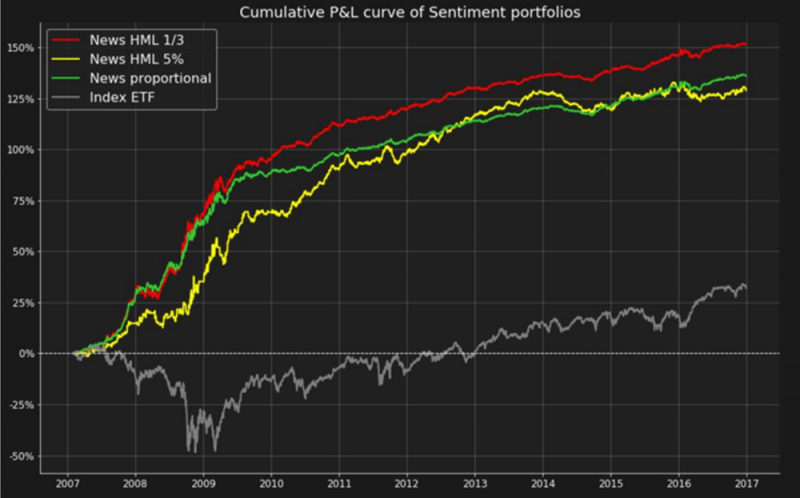
- Estratégias beta inteligentes: uma outra forma de utilizar dados para elaborar uma estratégia de negociação é encontrar um conjunto de características que representam as condições do mercado e, então, definir uma lista de fatores ou estratégias. A tarefa de aprendizagem é estabelecer uma ligação entre as condições do mercado em um momento específico e a melhor estratégia para aplicar no próximo período.
Exemplos de características que podem ser utilizadas para definir condições de mercado são: retorno SPX; nível VIX; inclinação da curva de rendimento; spread de crédito e inflação. Exemplos de estratégias são: portfólios com ativos ponderados de acordo com o valor/rank de um parâmetro, como o beta dos portfólios e diferentes fundos beta inteligente, como aqueles associados aos fatores Fama e French, áreas geográficas ou setores industriais.
A aprendizagem supervisionada consiste em aprender, durante o período de treinamento, a associação entre as estratégias mais rentáveis e as condições de mercado correspondentes. Quando o sistema aprende estas associações e pode imitá-las, ele é testado em um período fora da amostra.
Este gráfico exibe o benefício de aprender como formar dinamicamente um portfólio de acordo com quantis beta e como ele supera um portfólio comum longo-curto.
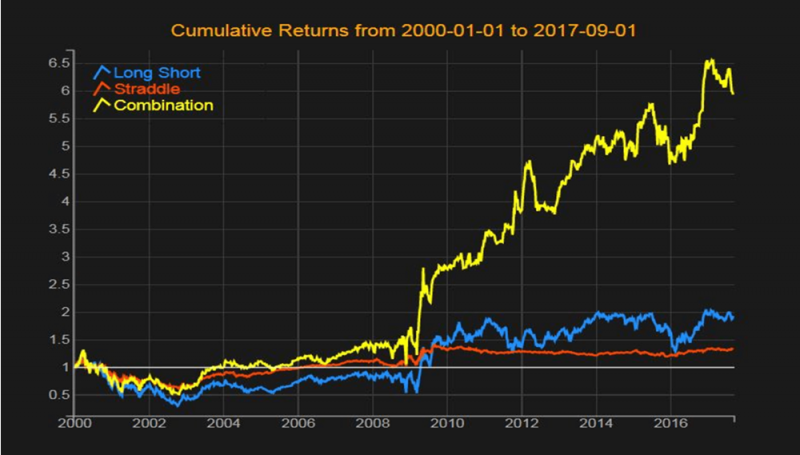
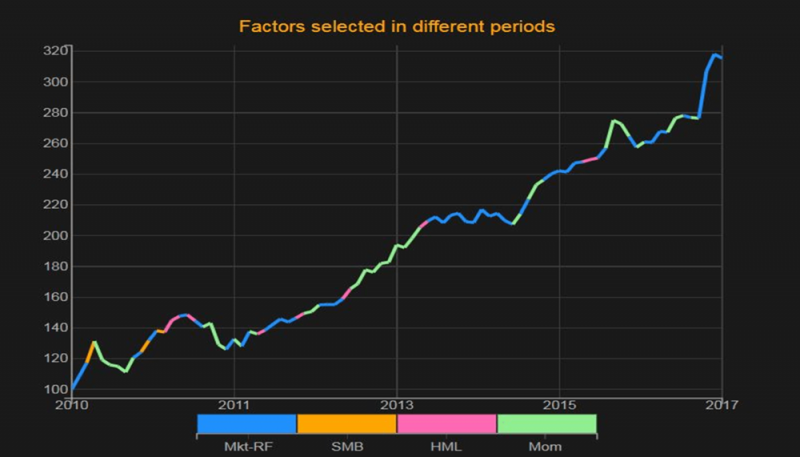
Este gráfico mostra a estratégia ideal selecionada para a construção de uma estratégia de rotação dos portfólios de fator Fama-French:
A disponibilidade de novos conjuntos de dados e técnicas, e aumentos na potência de computação ampliou as aplicações de aprendizagem de máquina (machine learning) em finanças. O campo ainda é novo e cheio de ciladas mas é promissor à medida que uma nova geração de técnicas, ferramentas e talentos começa a descobrir o seu potencial completo.